Once upon a time, I didn’t: within a few years of university, I managed to blow through all my savings, loans, grants, parental support, and overdraft. There were times where I couldn’t withdraw money from a cash machine because I had less than £5 to my name (well, less than -£1995 to my name, if you exclude the overdraft). I had to carefully plan around the monthly income my parents gave me, and sometimes had to delay rent payments. And then I decided to do a Ph.D: which I didn’t get funding for, and would have to pay for myself.
The situation was untenable, things had to change: I started tracking all my spending. Then, when I knew where the money was going, I started to budget and to rein my spending in.
I’ve now been tracking my finances, down to the penny, with entirely manual data entry, since 2016. And I couldn’t imagine doing it any other way.
Principles
I’ve essentially adopted the You Need A Budget (YNAB) principles, though I don’t use the actual YNAB software (more on that later). I’ve also drawn inspiration from the /r/ukpersonalfinance flowchart.
My personal finance principles are:
Track everything, by hand.
Every transaction I make, I note down in my journal. Having the data lets me analyse it and establish goals, and doing it by hand gives me a greater appreciation of where my money is going (as well as adding a little extra friction per-transaction, which sometimes is enough to avoid an impulse-purchase).
Use envelope budgeting for short-term money.
I consider my bank account “empty”, in a sense: there’s no money in the account itself, all the money is in subaccounts allocated to specific purposes, like rent or food or web servers. And those purposes are specific: there’s no “savings” category, for instance. My bank doesn’t actually provide these subaccounts, they’re just something in my tracking, but some banks (like Monzo and Starling) do.
I’ve specified “short-term” here because I don’t envelope-budget my long-term investments: I’m not going to touch those for 5 to 10 years, or longer, so there’s no way I can predict how I’ll want to use them.
Budget everything monthly.
Like most people in the UK, I get paid once a month. So it’s easy to budget for monthly expenses like rent or utilities. There’s a consistent amount spent every month, so I can just allocate that much of my monthly income to pay for it. Somewhat harder are the expenses which occur less frequently: it’s easy to forget about these, not budget for them in advance, and then rush to find the money to pay for them.
But these infrequent expenses can be treated as a monthly expense, by dividing the cost by 12 (or by however many months are between payments on average) and budgeting that much every month. Then when the expense comes around, the money has been put aside.
A model is only useful if it reflects reality.
If I’m consistently over- or under-spending in a budget category, the budget needs to change. For example, there is absolutely no use in budgeting £200 for food every month if I always overshoot that by getting a bunch of takeaways and have to make up the difference elsewhere: much better to budget the actual amount, and then work to reduce how many takeaways I get until I’m consistently spending under my target.
The purpose of tracking everything and of making budgets is so that I can make predictions about the future. But those predictions are worthless if the data used to produce them is unrealistically optimistic or just downright wrong.
Save more than you spend.
Every month, I should save (as cash or by investing) more than I spend. If I spend all my income, I’m living paycheque to paycheque, and that means any disruption or reduction in my income could be dangerous; and if I spend all my income and then some, I’m gradually running out of money.
These principles have lifted me out of financial ruin (or close to it), and set me on the path to wealth. Sure, I also have a high-paying job, which helps a lot; but if I had the same spending habits now that I did in my university days, I would have almost no savings and would be living in fear of how I would survive if I were to lose my job.
Tracking, metrics, and SMART goals
Lots of people use YNAB, or Excel, or Google Sheets to track their spending. I use plain-text accounting, specifically, hledger. The tool you use doesn’t actually matter, so long as it works for you. Nor do you need to track down to the penny, as I do. Some people round all their spending to the nearest pound, or even larger amounts, and track that. Some people don’t track cash, and just mark any money they withdraw as “spent”.
It’s more important that you do enough tracking to help you meet your goals. Don’t let the perfect be the enemy of the good.
Metrics
While the most straightforward metric of financial health is the monthly change to my assets (positive is good: I’m saving more than I spend; negative is bad: I’m spending more than I save; zero is kind of bad: I’m spending everything), there are a few other metrics I look at.
Firstly, there are two metrics which I don’t generally see mentioned online, but they’re valuable to me because I can use them to compute other, more directly useful, metrics:
Average daily expense:
This is the total money spent over the period (excluding anything taken before income hits my bank account: like income tax or my student loan), divided by the number of days in the period.
As a Prometheus time series, this is:
( sum(hledger_balance{account="expenses"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses:gross"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="expenses:gross"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_windowLet’s break that down:
hledger_balancesis a time series of end-of-day account balances. It has labelsaccountandcurrency.hledger_fx_rateis a time series of daily currency exchange rates, which I collect at 9PM UK time. It has labelscurrency(so it can be combined easily withhledger_balances) andtarget_currency.{account="expenses"}is the parent account of all other expense accounts, so it contains their balances too. All expense accounts are strictly positive: money moves intoexpensesfrom other accounts.{account="expenses:gross"}is the account I use to track deductions from my gross pay.$currencyis a Grafana dashboard variable, defining the currency I want to see the result in, usually that’sGBP.1$agg_windowis another dashboard variable, defining the number of days to look at to work out that average, usually 365.
So this is saying “take the expenses (excluding pay deductions) now and
$agg_windowdays ago, subtract them to work out how much I’ve spent over that entire time, and divide by$agg_windowto work out the average daily spend.”Average daily income:
This is the total income over the period (excluding gifts), divided by the number of days in the period.
The Prometheus expression is pretty similar to the average daily expense:
( sum(hledger_balance{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="income"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="income:gift"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="income:gift"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_window * -1The
* -1at the end is because all theincomeaccounts are strictly negative (money moves out ofincomeinto other accounts).
Now we can compute some more interesting metrics.
Net worth:
If I paid off all my debts right now, how much money would I have left?
sum(hledger_balance{account="assets"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) + on(target_currency) sum(hledger_balance{account="liabilities"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency)For the same reason as
income,liabilitieshere is strictly negative.You could exclude things that aren’t “real” debts here, like a student loan, if you wanted. But I include it.
Savings rate:
For every calendar month (since I get paid monthly) divide the saved income by the net income, then take the average of all those values.
# saved income ( sum(hledger_monthly_decrease{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) - on(target_currency) sum(hledger_monthly_increase{account="expenses"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) ) / on(target_currency) # net income ( sum(hledger_monthly_decrease{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) - on(target_currency) sum(hledger_monthly_increase{account="expenses:gross"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) )There’s no explicit averaging in this expression because Grafana does that for me.
This uses a couple of new metrics:
hledger_monthly_decreaseis the amount of money moved out of the account (as a non-negative number) in that calendar month.hledger_monthly_increaseis the amount of money moved in to the account (as a non-negative number) in that calendar month.
Unfortunately I can’t just use
hledger_balancesfor this because Prometheus doesn’t allow aggregating data by calendar month, and months are not all the same length. But even if it could, I think this approach would still end up being more straightforward. Before migrating to Prometheus, I used a significantly more complicated InfluxDB-based dashboard, which did attempt to work out savings rate from the balances. It was pretty complex, and also would wrongly count receiving a loan (a liability) as income.So this is saying that my saved income is the amount
incomehas gone down by (remember: money moves fromincomeinto other accounts) minus the amountexpenseshas gone up by. Whereas my net income is the amountincomehas gone down by (i.e., gross income) minus the amountexpenses:gross(pay deductions) has gone up by.An alternative formulation which excludes pension contributions would be:
# saved income ( sum(hledger_monthly_decrease{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) - on(target_currency) sum(hledger_monthly_increase{account="expenses"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) # ignore pension contributions (assumes pensions only go up - include 'decrease' as well to handle January roll-over) - on(target_currency) ( sum(hledger_monthly_increase{account="assets:pension"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) - sum(hledger_monthly_decrease{account="assets:pension"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) ) ) / on(target_currency) # net income ( sum(hledger_monthly_decrease{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) - on(target_currency) sum(hledger_monthly_increase{account="expenses:gross"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) # as above - on(target_currency) ( sum(hledger_monthly_increase{account="assets:pension"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) - sum(hledger_monthly_decrease{account="assets:pension"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by(target_currency) ) )Runway:
I’m sure there’s a better name for this, but this is the metric which tells me how many days I could survive with my current assets with no income. So, if I lost my job today with no severance pay, how long would I have to find a new one, assuming I keep my spending habits the same?
This comes in two forms: a “short runway” and a “long runway”.
The short runway only considers cash (whether physical cash or a bank account) and an emergency fund (if you have one of those)2:
# total available cash and emergency fund ( sum(hledger_balance{account="assets:cash"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on (target_currency) sum(hledger_balance{account="assets:investments:nsi:premium_bonds:emergency"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / on (target_currency) # average daily expense ( ( sum(hledger_balance{account="expenses"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses:gross"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="expenses:gross"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_window )The long runway considers all assets, including investments, as if they were sold today:
sum(hledger_balance{account="assets"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) / on (target_currency) # average daily expense ( ( sum(hledger_balance{account="expenses"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses:gross"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="expenses:gross"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_window )In practice, if I did suddenly lose my job, I’d change my spending habits. So these are pessimistic estimates. In general though I prefer financial estimates to be pessimistic, and not optimistic.
FIRE number:
Financial Indepence, Retire Early (FIRE) is a movement with the goal of aggressively saving and investing enough money so that you can live off the returns indefinitely, meaning you no longer need to work (though some choose to). It’s something that appeals to me: I like my job and my lifestyle, but I would like having the same lifestyle without a job significantly more.
The rule of thumb is that if you have 25 years worth of expenses invested, you can withdraw one year’s expenses (4%) every year without the value of your investments decreasing, assuming an annual 7% growth and 3% inflation.
# average daily expense ( sum(hledger_balance{account="expenses"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="expenses:gross"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="expenses:gross"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_window # $fire_annual_factor years worth * 365 * $fire_annual_factorHere
$fire_annual_factoris 25. I just made it a variable so I could give it a clear name.AAW / PAW thresholds:
The Millionaire Next Door, a study of wealthy Americans, proposed a metric for wealth: if a person aged
Nyears old has an annual income of$D(excluding any inheritance), then they should have a net worth of$D * N / 10.Someone with under half that is an “under-accumulator of wealth” (UAW) and someone with more than double that is a “prodigious accumulator of wealth” (PAW).
So, the AAW threshold is the amount of money at which you are no longer a UAW:
( # average daily income ( sum(hledger_balance{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="income"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="income:gift"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="income:gift"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_window * -1 # $age/10 years worth * 365 * $age / 10 ) / 2 # ignore gifted income - on(target_currency) sum(hledger_balance{account="income:gift"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) # add (subtract) liabilities, other than student loan - on(target_currency) sum(hledger_balance{account="liabilities"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="liabilities:loan:slc"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency)And the PAW threshold is the amount of money at which you are no longer an AAW:
( # average daily income ( sum(hledger_balance{account="income"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="income"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) - on(target_currency) sum(hledger_balance{account="income:gift"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="income:gift"} offset ${agg_window}d * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) ) / $agg_window * -1 # $age/10 years worth * 365 * $age / 10 ) * 2 # ignore gifted income - on(target_currency) sum(hledger_balance{account="income:gift"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) # add (subtract) liabilities, other than student loan - on(target_currency) sum(hledger_balance{account="liabilities"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency) + on(target_currency) sum(hledger_balance{account="liabilities:loan:slc"} * on(currency) hledger_fx_rate{target_currency="$currency"}) by (target_currency)It turns out that the PAW threshold is below the FIRE number. This makes some degree of intuitive sense: becoming financially independent requires a prodigious amount of money! But, since the FIRE number does not exclude gifts, it’s possible to become financially independent by receiving a large inheritance which you then invest, but you may still be a UAW if you’re otherwise not very good at saving.
SMART goals
Once you’re tracking your finances and have some metrics of interest, even if it’s only something very simple like “total value of assets” or “net worth”, you can start to make goals. The best goals are SMART goals:
- Specific
- Measurable
- Achievable
- Relevant
- Time-limited
In the past I’ve set goals like:
- Pay off my overdraft
- Save 3 months expenses in cash
- Increase emergency fund balance to £5k
- Increase savings rate to 33%
And so on. I currently have a long-term goal of saving for a house deposit, but that will take a few more years to complete.
I also have targets for all the key metrics I track, and display those on a dashboard:
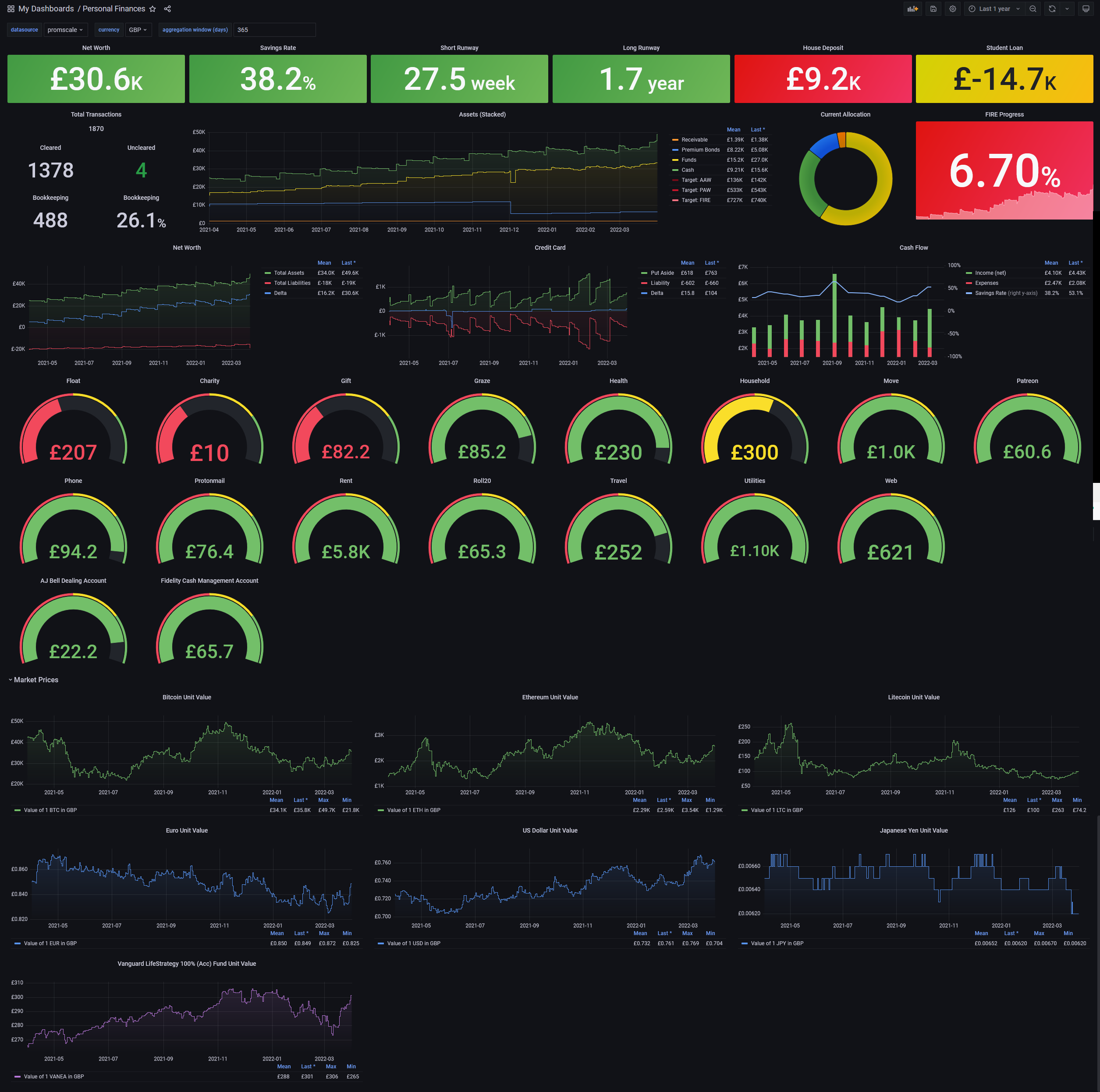
I wrote a script which imports the data every evening. Sometimes I’ll also make some plans for the future, mock up some data, and import that into the dashboard, so I can try out different savings plans, or think about how to allocate an expected payrise or bonus.
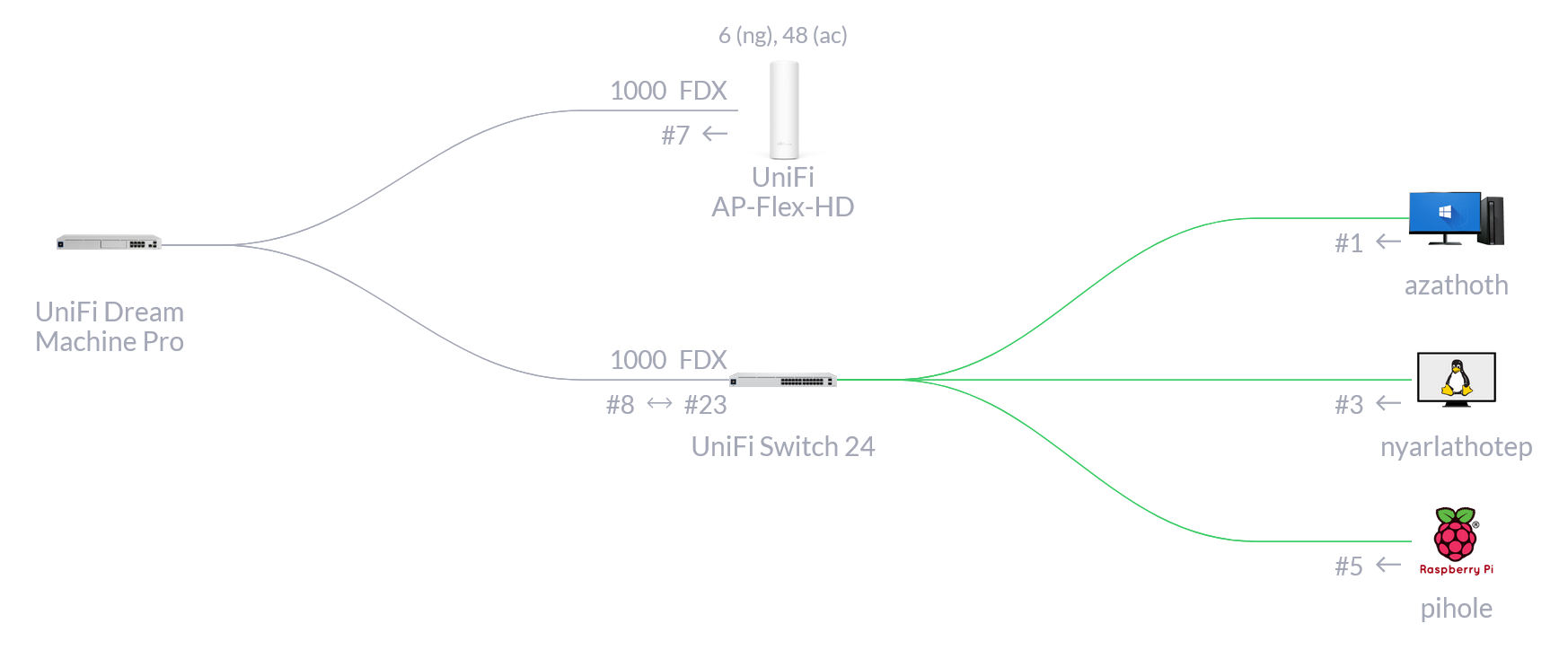
A high level view of the system
I have one main bank account, and everything is driven by activity in there. This bank account is where I do the bulk of my envelope budgeting, it’s where my income arrives, and it’s where standing orders transfer money from into other accounts and investments.
This is my Nationwide FlexDirect. I picked it because it had a good introductory interest rate.
It has four “types” of envelope, and many envelopes of each of these types:
Discretionary envelopes are for money I can spend however I want, and I usually spend the entire contents of these within a month, rather than building up savings.
Goal envelopes are for specific future expenses, like renewing my passport or visiting Japan.
Pending envelopes are to hold cash which is due to be sent elsewhere in the near future.
Saved envelopes are my regular budget categories: things like food, rent, travel, and so on.
I also have a few other accounts:
- A Starling bank account, for foreign currency transactions (as it doesn’t charge a conversion fee).
- A Marcus bank account, for cash savings.
- A Fidelity stocks and shares ISA, holding my long-term investments for the future.
- An AJ Bell stocks and shares LISA, holding half of my house deposit savings.
- A Premium Bonds account, holding the other half of my house deposit savings.
Both my ISA and LISA are invested in a low-cost Vanguard index fund.
Income allocation
On payday, money arrives in the Nationwide account. It’s split up between discretionary envelopes, goal envelopes, pending envelopes, and saved envelopes as appropriate. The allocations are fairly static, usually only changing when I intentionally change something in my process.
However, my income doesn’t necessarily exactly match my budget. There’s usually some excess income, which I allocate to two special accounts:
I add up to £125 to a “saved goals” envelope, if I don’t have any specific goal envelopes right now, to be used towards future goals.
I add any remainder to a “saved invest” envelope, which I’ll manually invest in my ISA when it reaches a reasonable amount (say, £100 or more).
Tracking transactions
As I spend or move money, I note down the transactions. I check all my statements once a week, on Saturday mornings, to reconcile and fix any inconsistencies. This only takes a few minutes.
I’m now very good at not having inconsistencies.
Credit card
I have an American Express credit card, because it gives me some cashback. There is a £25 annual fee, but the cashback more than covers it.
When I buy something with the card, I note that down as two transactions: one spending money from the card, and one transferring money from the relevant discretionary / saved / goal envelope into a “pending amex” envelope. The card is paid off in full, from that envelope, by a direct debit around the start of each month.
And that’s it!
It’s fairly straightforward. I think it’s important to keep things simple if you plan to stick to it. Most of the complexity in my personal finance system comes from manually entering all the data, and using the right envelopes.
Implementation details
As said earlier, I use hledger, which is a plain-text accounting tool. This section covers how I use hledger: it’s pretty conventional, but has lots of examples.
Journal files
I log all my financial transactions for the current year in a file called current.journal. There are $YEAR.journal files for historic data. I also have two files which all my journals include:
commodities, a list of all commodities (currencies, cryptocurrencies, funds) I deal with.prices, end-of-day exchange rates for all of my commodities.
Finally, I have a combined.journal file, which includes the journal files from 2020 onwards (as the start of 2020 marked the last big change to how I tracked things), along with appropriate closing transactions for each year so that they fit together. This file is used as the data source for the dashboard.
This is the template for a new journal file:
include commodities
include prices
* Starting balances
YYYY-01-01 ! Opening balances
...
* Ledger
** January
** February
** March
** April
** May
** June
** July
** August
** September
** October
** November
** DecemberFor each month, I fill in expected expenses, transfers, and income allocation based on previous months and my budget:
YYYY-MM-30 Expenses
# expected expenses (from previous months) go here
expenses:virtual
YYYY-MM-30 Transfers
# expected transfers (from budget) go here
YYYY-MM-30 Job
# expected income allocations (from budget) go here
income:jobI then comment out these expected transactions. They’re there to uncomment if I want to forecast, but for every-day use they’re hidden away.
Chart of accounts
The set of accounts I use is fairly stable: sometimes I’ll add one, or one will cease to be useful, but that’s a rare event. Here are all the regular accounts, which are mostly self-explanatory:
assetscashpaypalpettyhand—physical cash, in my walletbudgeted—…which was withdrawn from my bank accountunbudgeted—…which was a gift
home—physical cash, not in my wallet
marcussavings- subaccounts for specific categories
nationwideflexdirectdiscretionaryothersocialtea
goal- subaccounts for specific future expenses, like renewing my passport
pending- subaccounts for money to be transferred to other accounts
savedfoodgiftgoals—money to allocate to future goals, if I don’t have any right nowgraze—monthly Graze subscriptionhealthhouseholdinvest—money to invest, outside of my regular scheduled investmentsphonerenttravelutilities
starlingsavedpatreon—monthly Patreon subscriptions (charged in USD)protonmail—annual ProtonMail fee (charged in EUR)web—AWS, domain names, and hosting (all charged in foreign currencies)
investmentsajbellfidelitynsi
receivabledeposit—the deposit on my flat- subaccounts for people who owe me money
equity—used for special transactions (see below)expenses- subaccounts for various things
income- subaccounts for various things
liabilitiescreditcardamex
owed- subaccounts for people I owe money to
An account name is the path to it through the tree, separated by colons. For example, assets:cash, or expenses:utilities:electricity.
Money (and other commodities) is only stored in leaf accounts.
Marking transactions
hledger allows transactions to be marked with a ! or a *. The traditional meaning of these is “pending” and “cleared”.
I use ! slightly differently. I use it to indicate a transaction which is just an artefact of the way I track my finances, which doesn’t involve any balance changes to a real-world account.
For example, putting aside money to pay off credit card expenses:
2021-12-02 ! Bookkeeping
assets:cash:nationwide:flexdirect:saved:food -£29.35
assets:cash:nationwide:flexdirect:saved:household -£8.63
assets:cash:nationwide:flexdirect:saved:health -£5.20
assets:cash:nationwide:flexdirect:saved:gift -£119.00
assets:cash:nationwide:flexdirect:saved:gift -£22.43
assets:cash:nationwide:flexdirect:pending:amexIncome
Income is recorded as the pre-tax amount coming from income:$source, and is split across assets:* and expenses:gross:*. All amounts are included.
2021-11-30 * Cabinet Office
assets:cash:nationwide:flexdirect:float £32.46
assets:cash:nationwide:flexdirect:discretionary:other £2.66
assets:cash:nationwide:flexdirect:discretionary:social £30.00
assets:cash:nationwide:flexdirect:discretionary:tea £30.00
assets:cash:nationwide:flexdirect:goal:clothes £25.00
assets:cash:nationwide:flexdirect:goal:monitor £25.00
assets:cash:nationwide:flexdirect:goal:phone £250.00
assets:cash:nationwide:flexdirect:goal:upgrades £25.00
assets:cash:nationwide:flexdirect:pending:ajbell £400.00
assets:cash:nationwide:flexdirect:pending:fidelity £500.00
assets:cash:nationwide:flexdirect:pending:premium_bonds £150.00
assets:cash:nationwide:flexdirect:pending:starling:patreon £8.00
assets:cash:nationwide:flexdirect:pending:starling:protonmail £5.00
assets:cash:nationwide:flexdirect:pending:starling:roll20 £10.00
assets:cash:nationwide:flexdirect:pending:starling:web £80.00
assets:cash:nationwide:flexdirect:saved:food £200.00
assets:cash:nationwide:flexdirect:saved:gift £0.00
assets:cash:nationwide:flexdirect:saved:graze £18.95
assets:cash:nationwide:flexdirect:saved:health £0.94
assets:cash:nationwide:flexdirect:saved:household £70.99
assets:cash:nationwide:flexdirect:saved:phone £13.92
assets:cash:nationwide:flexdirect:saved:rent £1406.21
assets:cash:nationwide:flexdirect:saved:travel £0.00
assets:cash:nationwide:flexdirect:saved:utilities £237.67
expenses:gross:tax:income £1145.27
expenses:gross:tax:ni £439.80
expenses:gross:liabilities:loan:slc £375.00
expenses:gross:pension £345.09
income:job -£5826.96
expenses:gross:pension £1309.93
income:job -£1309.93
2021-11-30 ! Student Loan
expenses:gross:liabilities:loan:slc -£375.00 = £0.00
liabilities:loan:slcAll the postings in an income transaction should be for assets, expenses:gross, or income, so that my net income can be easily calculated as “decrease in income - increase in expenses:gross”, as in the metrics above. So student loan repayments are handled slightly awkwardly, but the ease of calculation is worth it.
Some income transactions may not have anything to do with expenses or liabilities:
2021-12-01 * Starling
assets:cash:starling:saved:web £0.05
income:interestInvestments
I use the @@ form to exactly specify the overall price:
2021-08-10 * AJ Bell
assets:investments:ajbell:lisa 1.6458 VANEA @@ £473.51
expenses:fees £1.50
assets:investments:ajbell:lisaTransferring the cash to the investment account and then investing it may be two separate steps:
2021-08-02 * Fidelity
assets:investments:fidelity:isa £500.00
assets:cash:nationwide:flexdirect:pending:fidelity
2021-08-09 * Fidelity
assets:investments:fidelity:isa 1.75 VANEA @@ £500.00
assets:investments:fidelity:isaIf there isn’t enough cash in the account to pay for any fees, some other asset will be sold. That’s bad, so I always make sure there’s some cash.
Expenses
Expenses from a bank account or debit card are straightforward:
2021-09-06 * Three Rivers District Council
expenses:tax:council £128.00
assets:cash:nationwide:flexdirect:saved:rentForeign currency expenses are recorded like so:
2021-01-04 * Hetzner
expenses:web 38.16 EUR @@ £34.52
assets:cash:starling:saved:webSpending physical cash
When I withdraw physical cash, I take it from the relevant budget category directly:
2019-01-25 * Withdraw
assets:cash:petty:hand:budgeted £10.00
assets:cash:nationwide:discretionary:other
2019-01-25 * Post Office
expenses:other £1.01
assets:cash:petty:hand:budgetedForeign currency cash withdrawals are treated exactly the same as investment transactions, using @@ to note down the exact exchange rate I got.
Using a credit card
When I pay for something on my credit card I add a transaction from liabilities to track the debt, and also remove the money from the budget category:
2021-12-06 * Tesco
expenses:food £24.73
liabilities:creditcard:amex
2021-12-06 ! Bookkeeping
assets:cash:nationwide:flexdirect:saved:food -£24.73
assets:cash:nationwide:flexdirect:pending:amexI pay off my credit card in full every month automatically via direct debit:
2021-12-03 * American Express
liabilities:creditcard:amex £520.97
assets:cash:nationwide:flexdirect:pending:amexEvery year, I get cashback. As the cashback goes to the balance on the card, rather than being paid into my bank account, I treat it as a pair of an income transaction and an allocation transaction:
2021-08-14 * American Express | cashback
liabilities:creditcard:amex £105.64
income:amex
2021-08-14 ! Allocation | cashback
assets:cash:nationwide:flexdirect:goal:amex_membership £25.00
assets:cash:nationwide:flexdirect:saved:health £80.64
assets:cash:nationwide:flexdirect:pending:amex -£105.64Pre-orders, kickstarters, etc
These are kind of like credit card transactions: I incur an expense, but the money isn’t actually taken for a while. In this case, “a while” could be months.
I put aside the money immediately:
2022-02-04 ! Kickstarter | Knock! Issue Three
assets:cash:nationwide:flexdirect:pending:preorder £38.00
assets:cash:nationwide:flexdirect:discretionary:otherAnd then note down the expense when it happens. Sometimes the amount I put aside won’t be quite right (e.g. if it’s a transaction in another currency, and I estimated the initial amount based on then-current exchange rates), so I’ll need to add or remove some money:
2022-03-06 * Kickstarter | Knock! Issue Three
expenses:ttrpg £32.43
liabilities:creditcard:amex
2022-03-06 ! Bookkeeping | Kickstarter | Knock! Issue Three
assets:cash:nationwide:flexdirect:pending:amex £32.43
assets:cash:nationwide:flexdirect:discretionary:other £5.57
assets:cash:nationwide:flexdirect:pending:preorder -£38.00I used to track this sort of thing by putting the money in pending:amex immediately, without going via pending:preorder. But that only works if I pre-order everything with my credit card, and also means that pending:amex almost never matches liabilities:creditcard:amex, which makes it easier to lose track of things. So I introduced this new account to make everything more explicit.
Maintenance
Weekly
Every Saturday I check my financial statements and reconcile transactions in the journal:
- For every transaction in the statement, find the corresponding journal transaction and mark it.
- If there are transactions missing from the journal, add and mark them.
- If there are transactions missing from the statement, the institution is being slow; reconcile as they come in over the next few days.
- If all transactions have cleared but the balance is not what is expected, figure out what happened and fix it.
- Check the balance in my wallet and mark all
handtransactions.
If any of the account balances are incorrect, and I can’t find the mistake, give up and fix it with a transaction to/from equity:adjustment. For example:
2020-12-04 ! Adjustment
liabilities:creditcard:amex -£76.15 = -£220.26
equity:adjustmentI don’t like making these adjustment transactions, and I’m pretty good at avoiding them now.
Annually
At the end of December, I finish up the journal to start the new year:
- Reconcile transactions.
- Write off any small amounts owed between friends with a transaction to equity.
- Rename the current journal file from
current.journalto$YEAR.journal. - Create a new
current.journal. - Generate opening / closing transactions with
hledger close:- Add the old journal file and the closing transaction to
combined.journal - Add the opening transaction to the new journal
- Add the old journal file and the closing transaction to
Here’s an example of a (2) transaction:
2020-12-31 ! Write-off
assets:receivable:adam -£11.95 = £0.00
liabilities:owed:jake £10.94 = £0.00
equity:writeoffHere’s an example of a (5.1) transaction:
2021-01-01 ! Closing balances
assets:cash:nationwide:flexdirect:pending:amex £-598.01 = £0.00
assets:cash:nationwide:flexdirect:pending:cavendish £-200.00 = £0.00
assets:cash:nationwide:flexdirect:pending:starling:patreon £-8.00 = £0.00
assets:cash:nationwide:flexdirect:pending:starling:protonmail £-5.00 = £0.00
assets:cash:nationwide:flexdirect:pending:starling:roll20 £-5.00 = £0.00
assets:cash:nationwide:flexdirect:pending:starling:web £-55.00 = £0.00
assets:cash:nationwide:flexdirect:saved:food £-200.57 = £0.00
assets:cash:nationwide:flexdirect:saved:graze £-50.00 = £0.00
assets:cash:nationwide:flexdirect:saved:health £-500.00 = £0.00
assets:cash:nationwide:flexdirect:saved:household £-300.00 = £0.00
assets:cash:nationwide:flexdirect:saved:phone £-100.00 = £0.00
assets:cash:nationwide:flexdirect:saved:rent £-2475.86 = £0.00
assets:cash:nationwide:flexdirect:saved:travel £-523.69 = £0.00
assets:cash:nationwide:flexdirect:saved:utilities £-800.00 = £0.00
assets:cash:petty:hand:budgeted £-19.05 = £0.00
assets:cash:petty:hand:unbudgeted £-2.00 = £0.00
assets:cash:petty:home -3.35 EUR = 0.00 EUR
assets:cash:petty:home -1853.00 JPY = 0.00 JPY
assets:cash:starling:saved:patreon £-21.79 = £0.00
assets:cash:starling:saved:protonmail £-42.43 = £0.00
assets:cash:starling:saved:roll20 £-37.33 = £0.00
assets:cash:starling:saved:web £-283.38 = £0.00
assets:investments:cavendish -19.66 VANEA = 0.00 VANEA
assets:investments:cavendish £-36.08 = £0.00
assets:investments:coinbase -10.00 EUR = 0.00 EUR
assets:investments:fundingcircle £-0.03 = £0.00
assets:investments:nsi:premium_bonds:emergency £-4475.00 = £0.00
assets:investments:nsi:premium_bonds:move £-3775.00 = £0.00
assets:receivable:deposit £-1384.62 = £0.00
assets:receivable:refund £-161.00 = £0.00
assets:pension:alpha -2653.00 £/yr = 0.00 £/yr
liabilities:creditcard:amex £598.01 = £0.00
liabilities:loan:slc £20468.52 = £0.00
equity:opening/closingAnd here’s an example of a (5.2) transaction:
2021-01-01 ! Opening balances
assets:cash:nationwide:flexdirect:pending:amex £598.01
assets:cash:nationwide:flexdirect:pending:fidelity £200.00
assets:cash:nationwide:flexdirect:pending:starling:patreon £8.00
assets:cash:nationwide:flexdirect:pending:starling:protonmail £5.00
assets:cash:nationwide:flexdirect:pending:starling:roll20 £5.00
assets:cash:nationwide:flexdirect:pending:starling:web £55.00
assets:cash:nationwide:flexdirect:saved:food £200.57
assets:cash:nationwide:flexdirect:saved:graze £50.00
assets:cash:nationwide:flexdirect:saved:health £500.00
assets:cash:nationwide:flexdirect:saved:household £300.00
assets:cash:nationwide:flexdirect:saved:phone £100.00
assets:cash:nationwide:flexdirect:saved:rent £2475.86
assets:cash:nationwide:flexdirect:saved:travel £523.69
assets:cash:nationwide:flexdirect:saved:utilities £800.00
;
assets:cash:petty:hand:budgeted £19.05
assets:cash:petty:hand:unbudgeted £2.00
assets:cash:petty:home 3.35 EUR
assets:cash:petty:home 1853.00 JPY
;
assets:cash:starling:saved:patreon £21.79
assets:cash:starling:saved:protonmail £42.43
assets:cash:starling:saved:roll20 £37.33
assets:cash:starling:saved:web £283.38
;
assets:investments:fidelity 19.66 VANEA
assets:investments:fidelity £36.08
assets:investments:coinbase 10.00 EUR
assets:investments:fundingcircle £0.03
assets:investments:nsi:premium_bonds:emergency £4475.00
assets:investments:nsi:premium_bonds:move £3775.00
;
assets:receivable:deposit £1384.62
assets:receivable:refund £161.00
;
assets:pension:alpha 2653.00 £/yr
;
liabilities:creditcard:amex -£598.01
liabilities:loan:slc -£20468.52
;
equity:opening/closingYou might be wondering why I do the currency conversion one at a time for each account, rather than once at the end. This is because
FOO +on(FIELD) BAR(or any binary operator) will discard those entries ofFOOfor which there isn’t a corresponding entry ofBAR, it won’t assumeBARto be 0 in those cases. So this means that binary operators are lossy in PromQL! So to get around that issue, I convert all the series to the same currency before doing arithmetic on them.↩︎I’ve got rid of my dedicated emergency fund, since I have both a credit card and a few months regular expenses saved up. But I did have one in the past, so it’s taken into account in the short runway so that historic data works correctly.↩︎