Once upon a time I used a self-hosted instance of Jenkins and the free-for-open-source Travis CI for continuous integration (CI) and continuous deployment (CD). It worked, but had some undesirable traits:
- There wasn’t any rhyme or reason over what ended up where.
- Travis often took a long time to run jobs.
- Jenkins was almost all hand-configured, with little config in version control.
I’m a big fan of configuration-as-code, and when I was exposed to Concourse CI at work, which does everything through configuration files and environment variables, I decided to replace my Jenkins set-up and migrate some of my Travis projects as a learning experience.
Eventually I ended up with Concourse doing continuous deployment, and Travis solely for continuous integration. This worked well, until the future of the free-for-open-source Travis became uncertain, and I decided to move away.
As luck would have it, we were discussing using GitHub Actions for CI at work at the time. I decided to switch to Actions as another learning experience.
Now I have GitHub Actions for CI on pull requests (PRs), and Concourse for CD of master branches. It works pretty well.
This memo talks through my practices, using this blog and dejafu as running examples. I’ll also cover how I run Concourse on NixOS, other related tools I use, and what my plans for future work are.
GitHub Actions
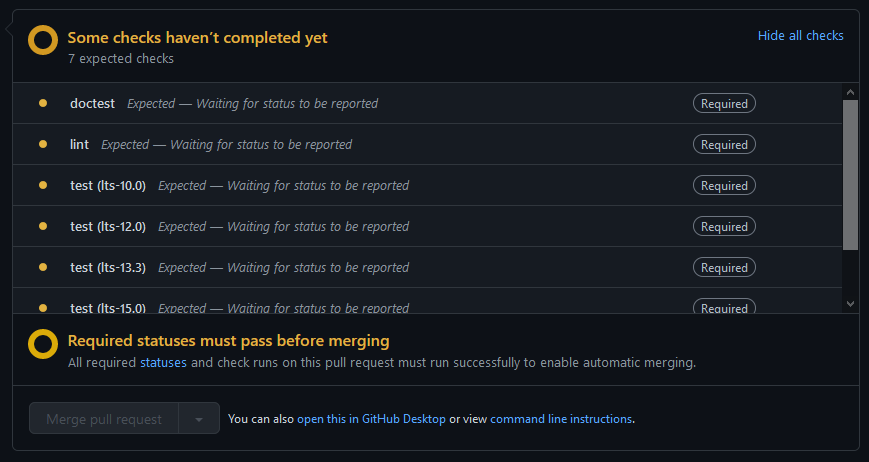
GitHub Actions is GitHub’s hosted CI/CD tool. It’s got good support for both official and community-maintained Actions (which are Docker images conforming to a simple specification), is as well-integrated into the rest of GitHub as you’d expect, and has a config file syntax not entirely unlike Travis.
Currently I’m inconsistent across my repos whether I require Actions to pass before a commit can make it into master. I tend to have that for my Haskell packages, because master gets deployed to Hackage, but allow pushing straight to master for other things.
Example: memo.barrucadu.co.uk
This is fairly typical of my Python projects: I have two jobs, which show up as two separate checks with their own logs in a PR, one to check for linting errors and one to check that the dependencies all install.
I’ve found that pip doesn’t have the most robust dependency solver, and can sometimes get confused and install mutually incompatible versions of packages. So for any PR which upgrades the dependencies, I like to ensure that the freeze file has a consistent set of versions.
If I wrote tests they would solve this problem too. But I don’t.
Example: dejafu
This is rather more complicated. I want to build the code and run the tests against all the supported versions of GHC, but for linting and doctests I just want to use the latest version. And I want the linting, doctests, and each of the main tests to run as separate jobs. This makes them run in parallel, and means that a failure in one doesn’t prevent the rest from running.
Like Travis, GitHub Actions supports matrix builds. The strategy part of the configuration means “run this job with each of these options; and don’t kill the rest if one fails”:
strategy:
fail-fast: false
matrix:
resolver:
- lts-9.0 # ghc-8.0
- lts-10.0 # ghc-8.2
- lts-12.0 # ghc-8.4
- lts-13.3 # ghc-8.6
- lts-15.0 # ghc-8.8
- lts-17.0 # ghc-8.10Another nice feature of GitHub Actions is that the documentation is well-written and easy to follow. Just about every option has a short example.
Concourse CI

Concourse CI is an opinionated “continuous thing-doer”. Everything is containerised and pure. No state is shared between jobs without you explicitly managing it, in the form of a “resource” (like a git remote, or an S3 bucket).
This was a big change when I came from Jenkins, which is just about as impure as you can get, but I’ve become a big fan of it. It makes jobs (potentially) reproducible, as they only depend on their inputs and on the pipeline configuration. You can have nondeterminism in your configuration, but you can’t get into trouble because of a previous build leaving things in a weird state.
I currently have 16 Concourse pipelines deploying a variety of things:
- My Haskell packages (by uploading a package to Hackage)
- My bookdb and bookmarks (by uploading a Docker image to my registry, and SSHing into a server to restart a systemd unit)
- A bunch of static websites
- My AWS and DNS configuration (these jobs automatically plan, but don’t apply until I click a button)
Example: memo.barrucadu.co.uk
This is another fairly typical pipeline, all of my static websites look largely like this. The one unusual feature is that it builds a Docker image: I need a few dependencies to deploy this site, like pandoc, so rather than install them on every deploy I build an image.
The deploy uses a custom rsync-resource that I took from somewhere and slightly tweaked. It also uses ((secrets)) in a few places.
The configuration is rather more verbose than GitHub Actions. It is doing more, but it also requires more to be spelled out. This can make large pipelines a bit difficult to read.
Example: dejafu
This is significantly more complicated. dejafu is a monorepo containing four Haskell packages and one set of tests, so this pipeline has jobs for testing & releasing each of those packages, as well as a job to run a nightly build when Stackage updates.
I use YAML anchors to reduce the repetition, which helps a bit, but it’s still a pretty long file.
This pipeline shows off Concourse’s task dependencies. All builds are triggered by a “resource” changing, but a job can specify that it should only be called for resources which passed a previous job.
For example, the release-concurrency job will be triggered by changes to the concurrency-cabal-git resource, but only after they pass the test-concurrency job:
- name: test-concurrency
plan:
- get: concurrency-cabal-git
trigger: true
- task: build-and-test
input_mapping:
source-git: concurrency-cabal-git
config:
<<: *task-build-and-test
- name: release-concurrency
plan:
- get: concurrency-cabal-git
trigger: true
passed:
- test-concurrency
- task: prerelease-check
params:
PACKAGE: concurrency
input_mapping:
source-git: concurrency-cabal-git
config:
<<: *task-prerelease-check
- task: release
params:
PACKAGE: concurrency
input_mapping:
source-git: concurrency-cabal-git
config:
<<: *task-releaseThese dependencies are what make up the visualisation in the screenshot above.
Other tools: Dependabot
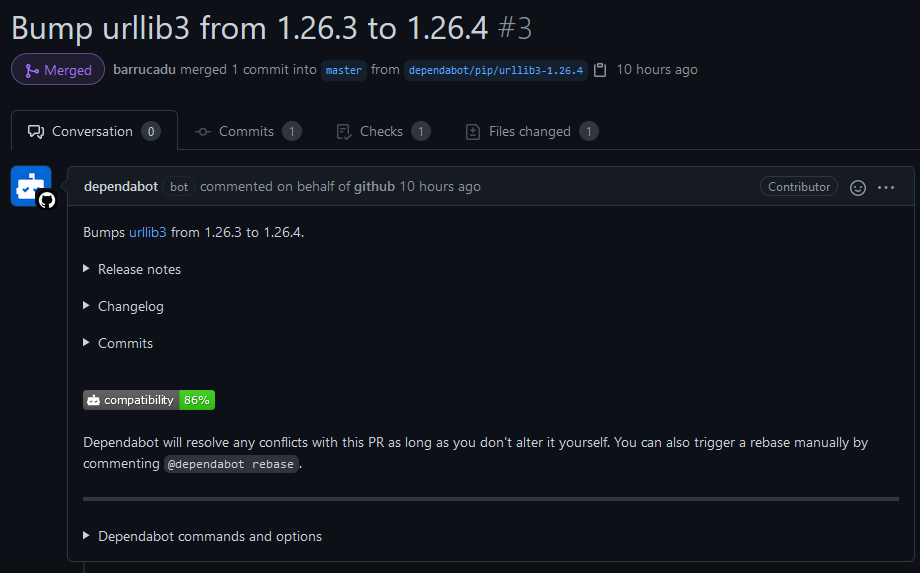
Dependabot is a handy little tool for automatically checking if you have any outdated dependencies, for a variety of ecosystems, and opening a PR to update them. It’s another tool we use at work (spotting a pattern?), but I didn’t pick this up to learn anything: it’s so simple there’s nothing really to learn, and its utility far outweighs the small configuration file you might want to write.
Example: memo.barrucadu.co.uk
This is one of my more complex Dependabot config files, which should hopefully convince you of how straightforward it is. It specifies I want PRs to update any official or community Actions, Dockerfile base images, or pip dependencies, that I’m using. And I want it to check daily (at 5AM UTC by default).
That’s it!
Example: dejafu
Unlike the other cases, this time dejafu has a simpler configuration than the blog. Dependabot doesn’t support Haskell, so all it’s doing is ensuring any Actions I’m using are kept up to date.
Since my Haskell packages are on Stackage, the Stackage maintainers let me know if I need to update a dependency.
Secrets Management
I don’t make a practice of needing secrets to build or run code in my public repos, so I don’t need to give GitHub Actions any secrets. It’s supported though, you can have both organisation-level and repository-level secrets.
My Concourse pipelines, however, do regularly need secrets. The password for my private Docker registry; the password to upload Haskell packages to Hackage; the SSH key to deploy this blog; and more!
Concourse has support for a few secret stores. I’m using the AWS SSM integration, mostly because it’s incredibly cheap, and means I don’t have to host and secure anything myself. It works well, I just need to set some environment variables giving Concourse an AWS access key hooked up to an IP-restricted policy granting SSM and KMS permissions. Almost no effort at all to set up if you already have an AWS account.
Running Concourse CI on NixOS
NixOS is my Linux distribution of choice and, while it has packages for many things, it does not have one for Concourse. However, there is an official docker image for Concourse.
I’ve got a systemd unit running Concourse in docker-compose:
systemd.services.concourse =
let
yaml = import ./concourse.docker-compose.nix {
httpPort = concourseHttpPort;
githubClientId = fileContents /etc/nixos/secrets/concourse-clientid.txt;
githubClientSecret = fileContents /etc/nixos/secrets/concourse-clientsecret.txt;
enableSSM = true;
ssmAccessKey = fileContents /etc/nixos/secrets/concourse-ssm-access-key.txt;
ssmSecretKey = fileContents /etc/nixos/secrets/concourse-ssm-secret-key.txt;
};
dockerComposeFile = pkgs.writeText "docker-compose.yml" yaml;
in
{
enable = true;
wantedBy = [ "multi-user.target" ];
requires = [ "docker.service" ];
environment = { COMPOSE_PROJECT_NAME = "concourse"; };
serviceConfig = {
ExecStart = "${pkgs.docker_compose}/bin/docker-compose -f '${dockerComposeFile}' up";
ExecStop = "${pkgs.docker_compose}/bin/docker-compose -f '${dockerComposeFile}' stop";
Restart = "always";
};
};Where the concourse.docker-compose.nix file is just some templated YAML. I’ve heard that you shouldn’t use systemd units to run Docker containers, for some reason, but it works and I run a few different services on a bunch of servers like this. Running Concourse in Docker also makes it easy to upgrade to a newer version, without needing to wait for an official package to be updated.
Future Work
I’m pretty happy with how things are working right now. Until recently I didn’t have Concourse secrets set up, and I was handling secrets by doing variable interpolation in my pipeline deployment script, and also I’d written everything in jsonnet for some reason. Setting up secrets, just using YAML, and removing the deployment script simplified things a lot.
I see GitHub advertising code scanning to me in all of my repositories, so maybe I’ll look into that next. I’m a big fan of static analysis, so having something which automatically scans my code for issues is very attractive.
The main thing I don’t have continuous deployment for is my NixOS configuration. I SSH into servers, run git pull && sudo nixos-rebuild switch like some sort of caveman! But automatically deploying that makes me a bit nervous, what if it goes wrong? Still, I switched to automatic updates recently, and nothing has broken yet, so maybe automatic configuration deployments are fine too.